Ok, we do dis now. The hype for AoD & Underrail already died down a bit, so we should get some decent results.
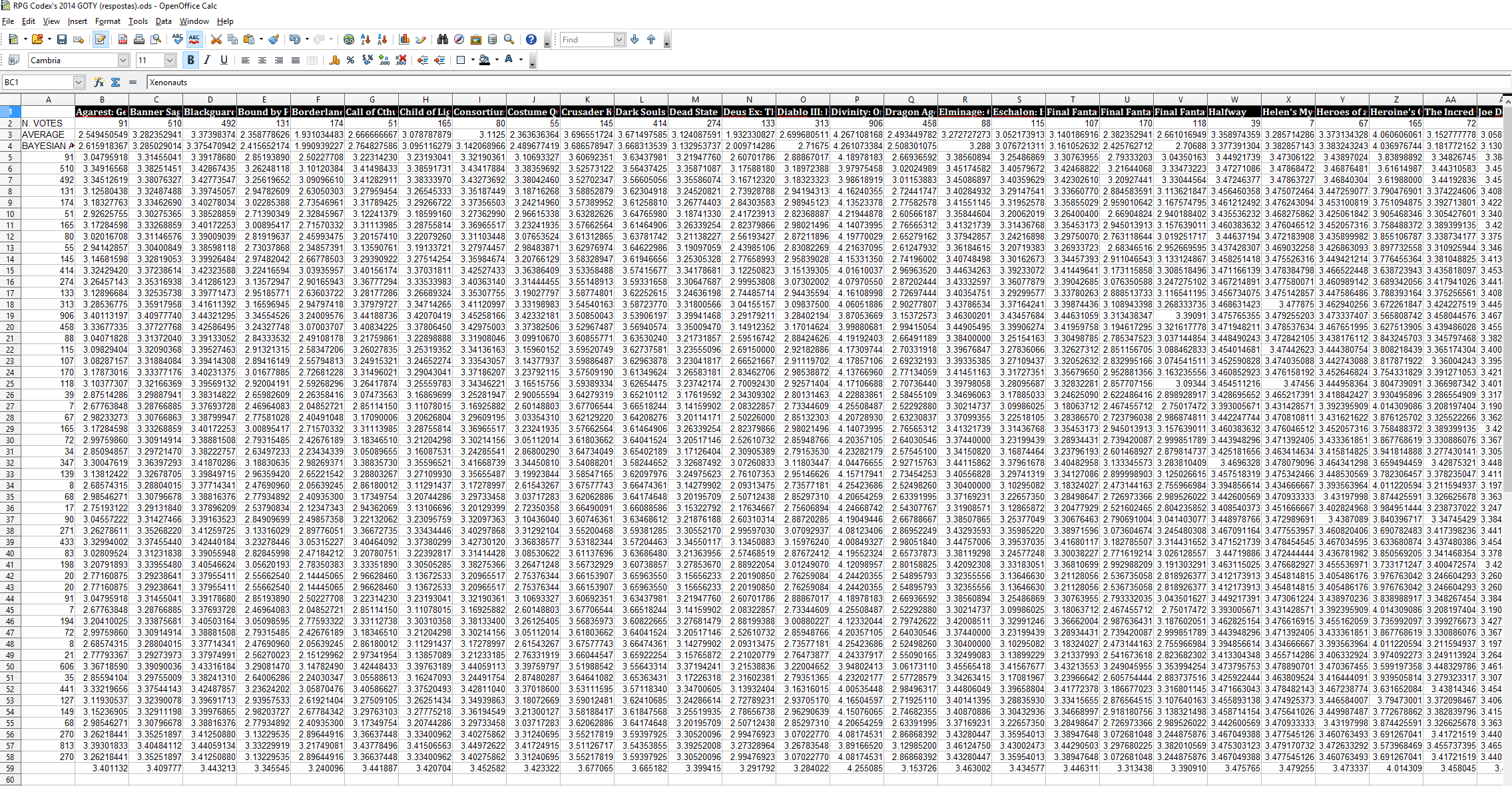
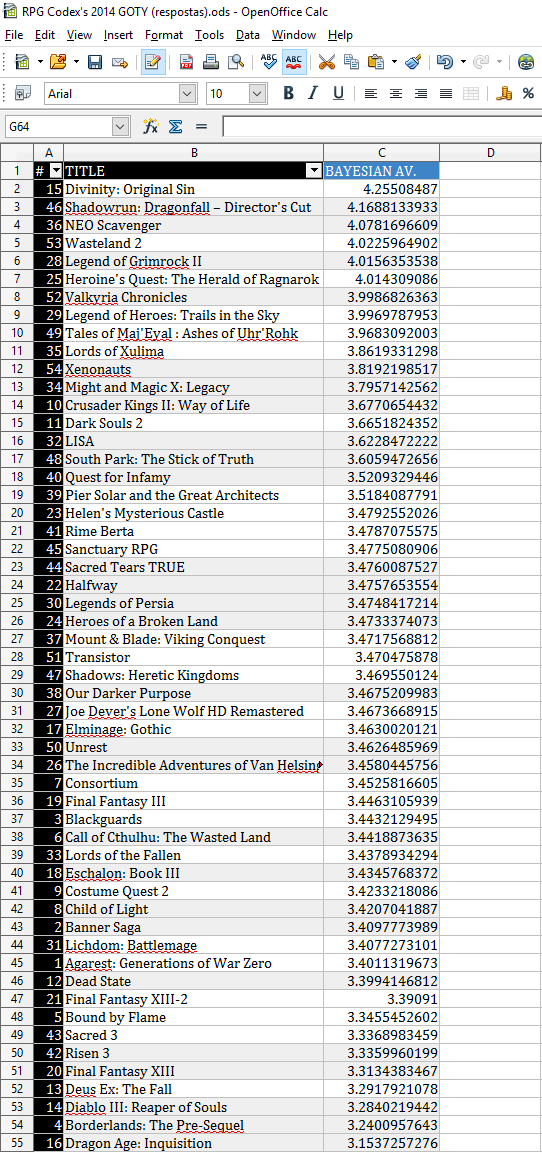
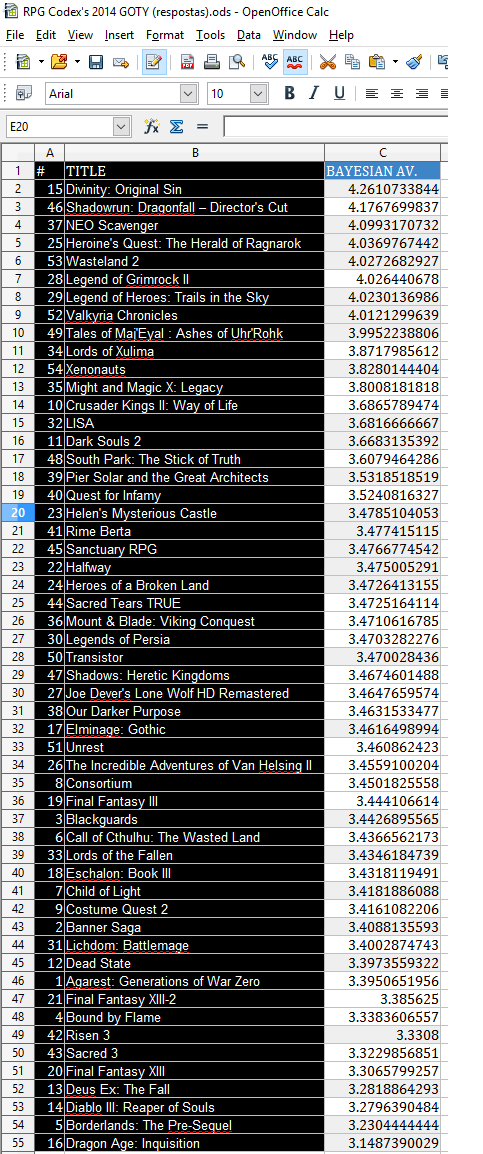
But before I even begin, let's get this out of the way: I intend to do a bayesian average, just like last time.
So, to avoid DRAMA (lol, like it's possible), does
toro ,
agris,
coffeetable and other math heads haev a better system they would like to purpose? or at least what "m" should be this time?
Damn. I have to remember shit.
Imho the voting methodology is pretty solid but it has two problems:
1. Multiple voting - last time some morons decided to vote multiple times and brag about it. Unfortunately this cannot be proved with the current voting system but the negative bias towards W2 was real.
2. The value of m can greatly impact the results - I still think m=7 was a major fuck up but I don't want to open the discussion again.
So, a better methodology means that you either solve the issues above or you try to mitigate their negative influences.
Multiple voting solution - I'm not sure if is possible but the voting should be open
only for the codex users with accounts created in 2015.
There is no solution for alts but at least the shitting on specific games will be contained.
The value of m solution - This is a little more complicated but almost anything is better than manually selecting the value of m.
Possible solution 1: Last year I actually proposed a solution which doesn't require manual selection of m value (see
http://www.rpgcodex.net/forums/index.php?posts/3701664)
The thing is, there is no way I can convince you that my solution is better unless I invest a lot of time in finding some mathematical/stochastic proof. I don't have the time or the abilities to do it.
The method is unorthodox (more like intuitive) but the results were quite "reasonable" and at least you can use it to verify that your results are not completely bonkers.
Possible solution 2: Real_M cannot be calculated but we know that (1) if m < Real_M then games with less votes will be advantaged and (2) if m > Real_M then games with more votes will be advantaged.
My proposal is to do the following iterative process:
step 1. Select m as being the minimal number of votes and calculate final scores,
step 2. Remove bottom 50% of the games,
step 3. Repeat from step 1 until you only have 5 games.
Possible solution 3. You sample results for multiple m and then you average the results:
Sample 1: m is equal to 0.10 * maximum number of votes a game received (10%)
Sample 2: m is equal to 0.20 * maximum number of votes a game received (20%)
Sample 3: m is equal to 0.30 * maximum number of votes a game received (30%) -----> with approximation Real_M can be anywhere from 20% to 40%
Sample 4: m is equal to 0.40 * maximum number of votes a game received (40%)
Sample 5: m is equal to 0.50 * maximum number of votes a game received (50%)
The problem is that in this case you replace manually selecting m with the selection of multiple intervals. However my hunch is that even this solution would provide better results than what you used before.
Now, I feel like say something along the lines "I might be retarded but I'm not stupid"
")
Bottom line is this: resolving both problems would be awesome but maybe it's not possible.
However anything is better than selecting m = minimal number of votes.
Anything.
So, what do you think? Please take your time for a decision. Or we could vote? :D